
Performance Engineering
Standard support offered by this lab includes code optimization, vectorization, and adoption of the code for GPU use. Novel tools for this lab will also be made available by our other method labs. The biggest potential in efficiency improvement is the algorithm itself and several joint projects with our user groups to improve the scientific software efficiency have led to improvements of typically more than one order of magnitude. Training activities include workshops on (parallel) programming, vectorization, GPU programming, debugging, and performance tuning.

AI and ML
AI is rapidly transforming nearly all scientific disciplines, with an ever-expanding ecosystem of techniques and tools. For individual researchers, keeping pace—let alone identifying and effectively applying the right solution—has become a major challenge. This method lab aims to help scientists navigate the evolving AI/ML landscape by providing targeted support tailored to their needs. We focus on visualization, debugging, and explainability—key components of Explainable AI—to foster deeper understanding and more efficient use of AI in concrete projects. We also support users interested in integrating domain-specific models with neural approaches, such as Hybrid or Neurosymbolic AI. Our services include tool deployment, optimization, and user training for frameworks like TensorFlow, PyTorch, and Caffe. In collaboration with other method labs, we are also addressing the limited HPC support in many AI tools to ensure scalable, high-performance integration.
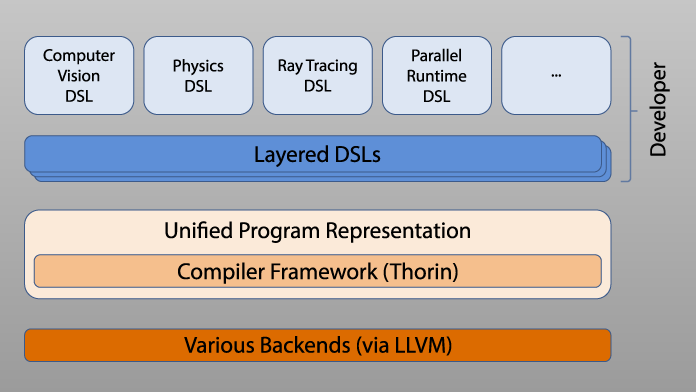
Parallel Programming Environments and Domain-Specific Compilation
Modern HPC systems increasingly rely on heterogeneous accelerators, posing major challenges for code portability and programmability. Legacy applications written in low-level languages like C/C++ are often ill-suited for these architectures.
This method lab supports the adoption of domain-specific languages (DSLs), which allow scientists to express application logic at a higher abstraction level while enabling efficient execution across diverse hardware. We focus on adapting AnyDSL and related technologies to user needs, offering regular tutorials and hands-on support for DSL implementation. Our expertise includes metaprogramming, DSL embedding, LLVM-based compilation, and automatic differentiation with tools like CoDiPack for high-performance derivative computations.
As HPC systems scale in size, parallel programming models become critical to maintain performance. We offer guidance and training in models such as MPI, GASPI, GPI-2, and task parallelism, along with consultancy for integrating these into existing codes. We also assist users with end-to-end HPC workflow setup, including advanced topics like differentiation workflows and parallel visualization.